How Do I Debug and Improve an AI Agent Application?
Adding Observability and Evaluation to AI Agent Application
Contents
Prerequisite
Key Concepts for Observability
- Tracing
- Logging
- Metrics
Fundamental Observability Stacks
- OpenTelemetry Protocol (OTLP) / OTEL Collector
- Architecture Example: https://yoshiblogswe.com/microservice_observability/
AI Agent
- Basic understand about how RAG, AgentLoop work
Real World Issues for Building AI Agent Product
Response Quality
- Empty Response
- Incorrect Response
- Takes too long for response
Root Cause is Usually Complex…
A generic agent loop can be represented as follows:
| |
This is essentially a Perceive → Think → Act → Observe loop
Same type of Error Can Come from Different Stage Fail
| Symptom | Potential root cause |
|---|---|
| Empty Response | LLM API error: timeout, rate limit, auth error, quota exceeded |
| Input context exceed the LLM max length |
| Symptom | Potential root cause |
|---|---|
| Incorrect Response | Tool returned malformed data |
| Context too long for model | |
| Poor parser extraction |
Product Spec
- Concurrency for upload files, chat SSE. Usually parsing file, embedding, LLM inference is performance bound which required for profiling
- The number of files that agent can response correctly. ex: For cross table analysis, you are potentially need so many files for LLM to infer the correct answer.
AI Agent Observability
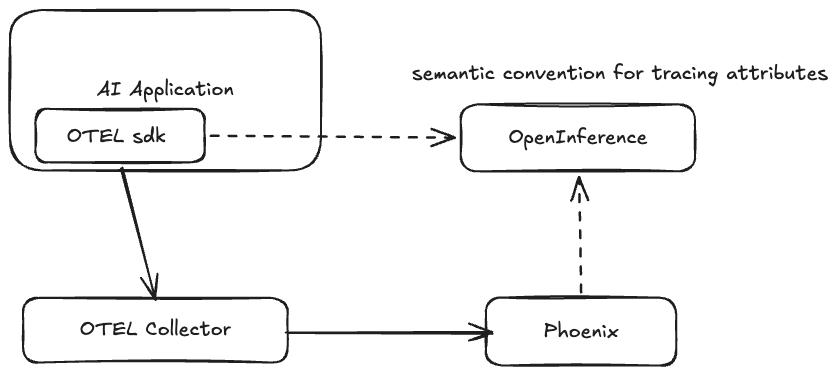
Phoenix
- Phoenix is an open-source observability platform designed specifically for LLM applications and AI agents.
- Highly recommend to use otel-collector instead of sending the traces directly to Phoenix, you potentially have
Jaegoror other tools receiving the tracing and metrics, having a centralized mediator could help to you loose dependency. A complex dataflow will add debug difficulty when errors happen.
File Process Profile: Parsing, Chunking, Embedding
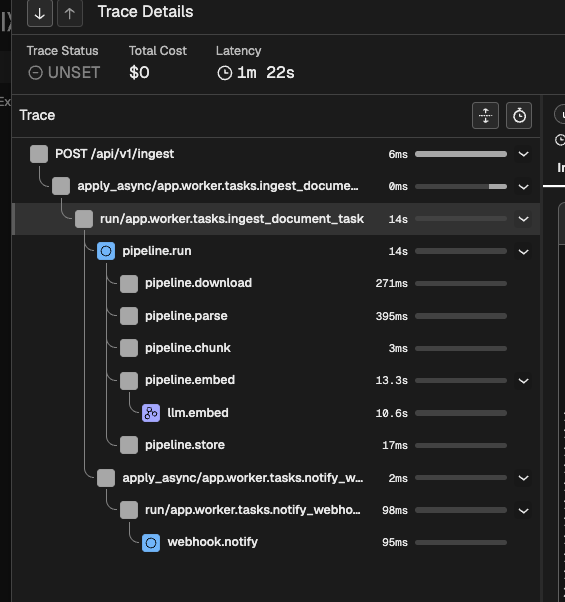
Agent Loop: LLM Inference, Tool Call, Memory, Truncate
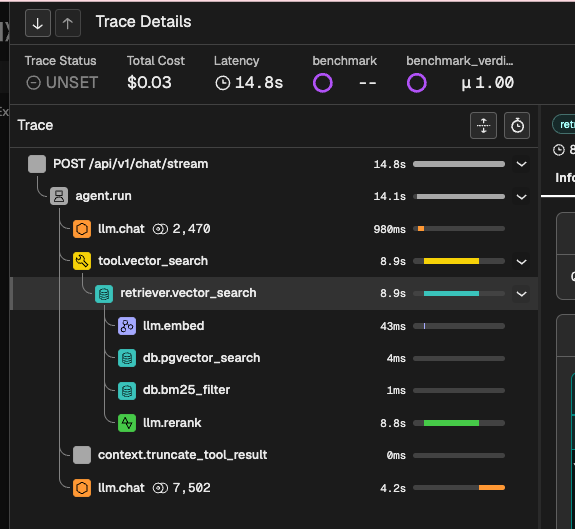
Implementation Notes
- It is always recommended to use AI agent framework like LangGraph, LangChain, which have already abstract the components for building agent, the framework itself can also well integrate with observability stack.
- It you are building agent without framework, I recommend you to self implement the decorator to manage the profiling works.
- Always remember to record input and output of truncate stages.
OpenInference
- OpenInference defines a common semantic convention for AI applications.
- With OpenInference, the AI application related attributes is able to render on Phoenix or fetch through OpenInference compatible sdk, ex: When designing benchmark, you may need to pull tracing from some published way, with OpenInference, no additional key name mapping works.
Benchmark Design
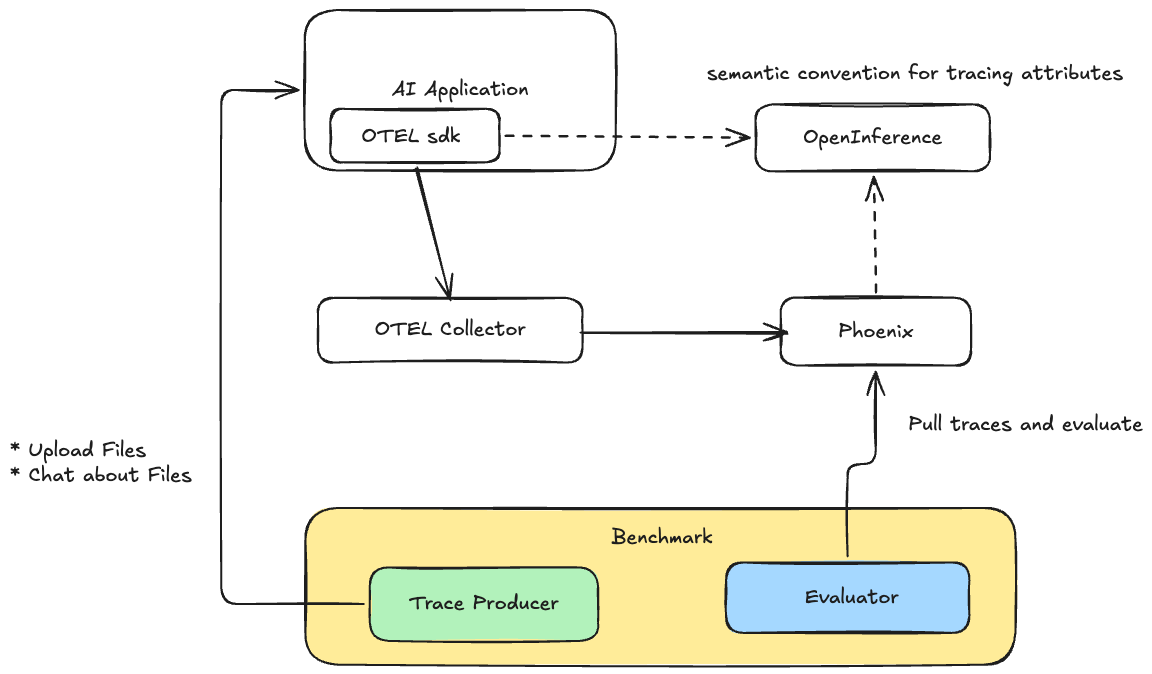
Directory Structure Example
| |
Command Design Example
Step 1: Upload the files from specified directory
| |
- User is able to assign for the concurrency number
- After upload finished (Include file processing), generate the report to profile the latency. (mean|med|p95)
Step 2: Chat about the files
| |
- User is able to assign for the concurrency number
- Questions should be read from somewhere of directory
- After chat finished, generate the report to profile the latency. (mean|med|p95)
Step 3: Evaluation
| |
- After chat finished, it supposed to produce a profiling csv file, each chat contain with
trace_id. - Evaluator use
trace_idto request for Phoenix, use input context, question, response for evaluation and generate report.
Evaluation
Generally evaluation can separate into 2 parts:
LLM Response
- The testing set (question) you provide may or may not contain with ground truth answer, but judge LLM still be able to label the confidence correctly in some extent (ex: Conflict with context or not, Answer correct or not).
- Advance: Design a feedback loop for labeling the ground truth.
- Advance: How to evaluate correctness of response with chat historical context?
Trajectory
- Agent Loop architecture involve with multiple stages, knowing the end response only is not enough for making improvement.
- Typically, we want to know the retrieval of the chunks, augentmented context is relevant to the question or not, the tool calling is enough or too much, or does rerank score the chunks correctly.
- This part is highly depends on design, I recommend to discuss with
claude codeor other LLM to design this specific part and I still working on this part.